Multilayer Perceptron and Neural Network¶
A Perceptron is an algorithm used for supervised learning of binary classifiers
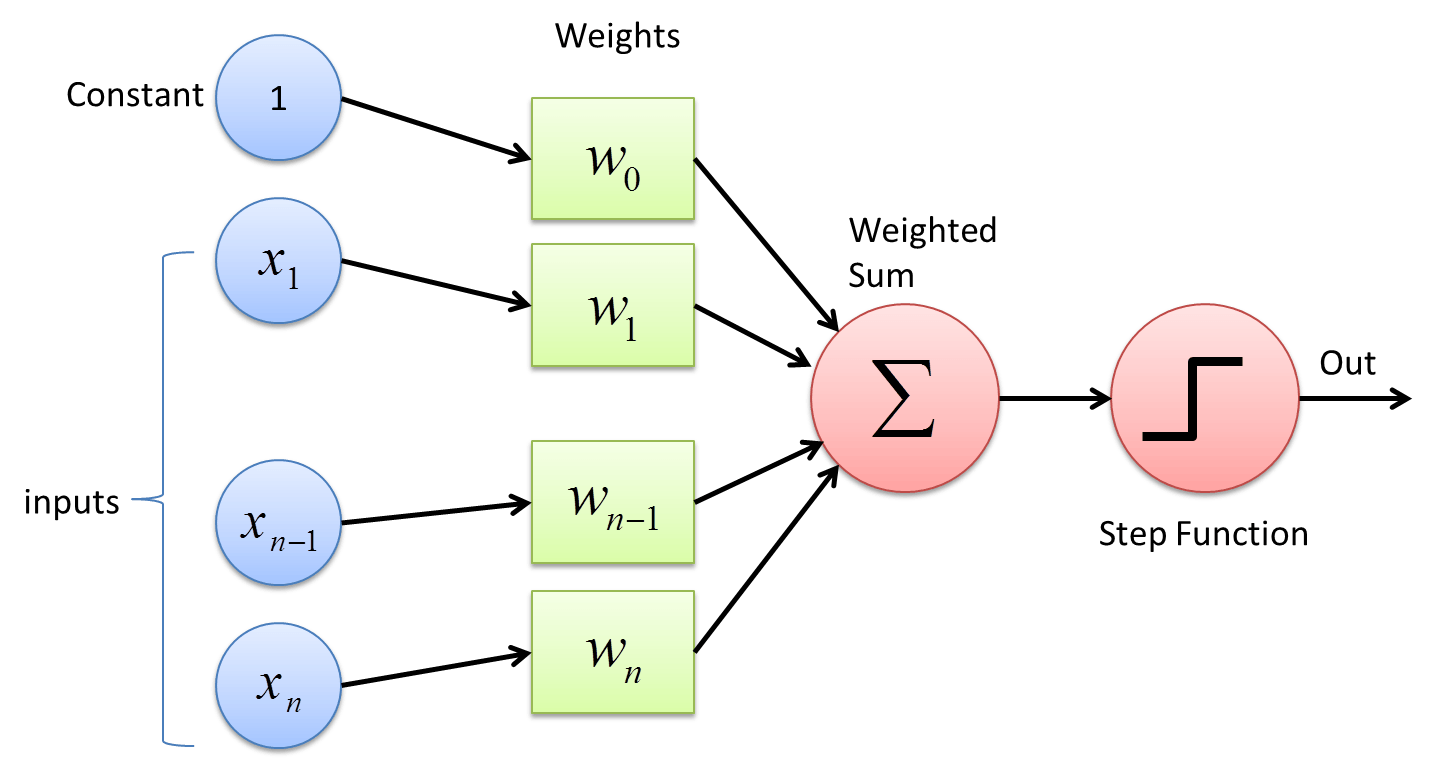
Update rule¶
$\mathbf{w}_{t+1}=\mathbf{w}_{t}+\left(1-H\left(y_{i} \mathbf{w}^{\top} \mathbf{x}_{i}\right)\right) y_{i} \mathbf{x}_{i}$
import numpy as np
import pandas as pd
from sklearn import datasets
class perceptron:
def __init__(self,lr=0.1,n_iter=200):
self.lr = lr
self.n_iter = n_iter
self.theta = None
def fit(self,X,y):
b = np.ones(X.shape[0])
b = b.reshape(b.shape[0],-1)
X = X.reshape(X.shape[0],-1)
X = np.hstack((b,X))
y = np.where(y==0,-1,1)
self.theta = np.random.rand(X.shape[1])
for _iter in range(self.n_iter):
for ind in range(X.shape[0]):
y_hat = self.theta.T.dot(X[ind])
if np.sign(y_hat) == y[ind]:
pass
else:
self.theta = self.theta + y[ind] * X[ind]
def predict(self,X):
b = np.ones(X.shape[0])
b = b.reshape(b.shape[0],-1)
X = X.reshape(X.shape[0],-1)
X = np.hstack((b,X))
pred = np.sign(X.dot(self.theta))
return np.where(pred==1,1,0)
def accuracy(self,pred,label):
return np.sum(pred==label)/len(label)
class perceptron:
def __init__(self,lr=0.1,n_iter=200,init_param='random'):
self.lr = lr
self.n_iter = n_iter
self.init_param = init_param
self.theta = None
def fit(self,X,y):
b = np.ones(X.shape[0])
b = b.reshape(b.shape[0],-1)
X = X.reshape(X.shape[0],-1)
X = np.hstack((b,X))
y = np.where(y==0,-1,1)
if self.init_param =='zero':
self.theta = np.zeros(X.shape[1])
elif self.init_param =='random':
self.theta = np.random.rand(X.shape[1])
else:
raise Exception("Wrong parameters initialization, initialize to zero or random")
for _iter in range(self.n_iter):
for ind in range(X.shape[0]):
y_hat = self.theta.T.dot(X[ind])
if np.sign(y_hat) == y[ind]:
pass
else:
self.theta = self.theta + y[ind] * X[ind]
def predict(self,X):
b = np.ones(X.shape[0])
b = b.reshape(b.shape[0],-1)
X = X.reshape(X.shape[0],-1)
X = np.hstack((b,X))
pred = np.sign(X.dot(self.theta))
return np.where(pred==1,1,0)
def accuracy(self,pred,label):
return np.sum(pred==label)/len(label)
iris = datasets.load_iris()
X = iris.data[:, :]
y = iris.target
y = (y>0)*1
data = np.hstack((X,y.reshape(-1,1)))
np.random.shuffle(data)
data = pd.DataFrame(data,columns=['Feature1','Feature2','Feature3','Feature4','Target'])
data.head(6)
model = perceptron(n_iter=300,init_param='random')
print('Model Pramenters: ',model.theta)
model.fit(X,y)
print('Model Pramenters: ',model.theta)
print('Training accuracy: ',model.accuracy(model.predict(X),y))
Multi-layer Perceptron¶
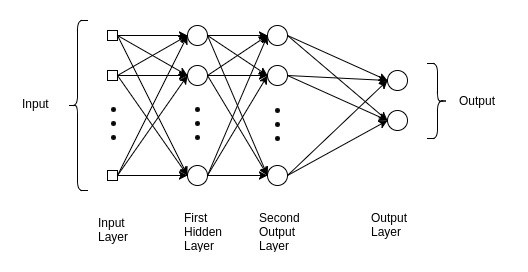
MLp are typically represented by composing together many different functions. $f(\boldsymbol{x})=f^{(3)}\left(f^{(2)}\left(f^{(1)}(\boldsymbol{x})\right)\right)$
Forward pass and back-prop¶
 $\frac{\partial L}{\partial W_{2}}=\frac{\partial L}{\partial X_{2}} \frac{\partial X_2}{\partial W_{2}}$
$\frac{\partial L}{\partial W_{2}}=\frac{\partial L}{\partial X_{2}} \frac{\partial X_2}{\partial W_{2}}$
$\frac{\partial L}{\partial W_{1}}=\frac{\partial L}{\partial X_{2}} \frac{\partial X_2}{\partial X_{1}} \frac{\partial X_1}{\partial W_{1}}$
Parameters update $W \leftarrow W-\alpha * \nabla_{w} L$
Example¶
Assume Mean squared error loss $L(X_2, Y) = ||X2 - Y||^2$
$\frac{\partial L}{\partial X_{2}} = 2(X_2 - Y)$
$\frac{\partial X_2}{\partial W_{2}} = X_1$
$\frac{\partial X_2}{\partial X_{1}} = W_2$
$\frac{\partial X_1}{\partial W_{1}} = X$
$\nabla_{w_2} L = 2(X_2 - Y)X_1$ and $\nabla_{w_1} L = 2(X_2 - Y)W_2X$
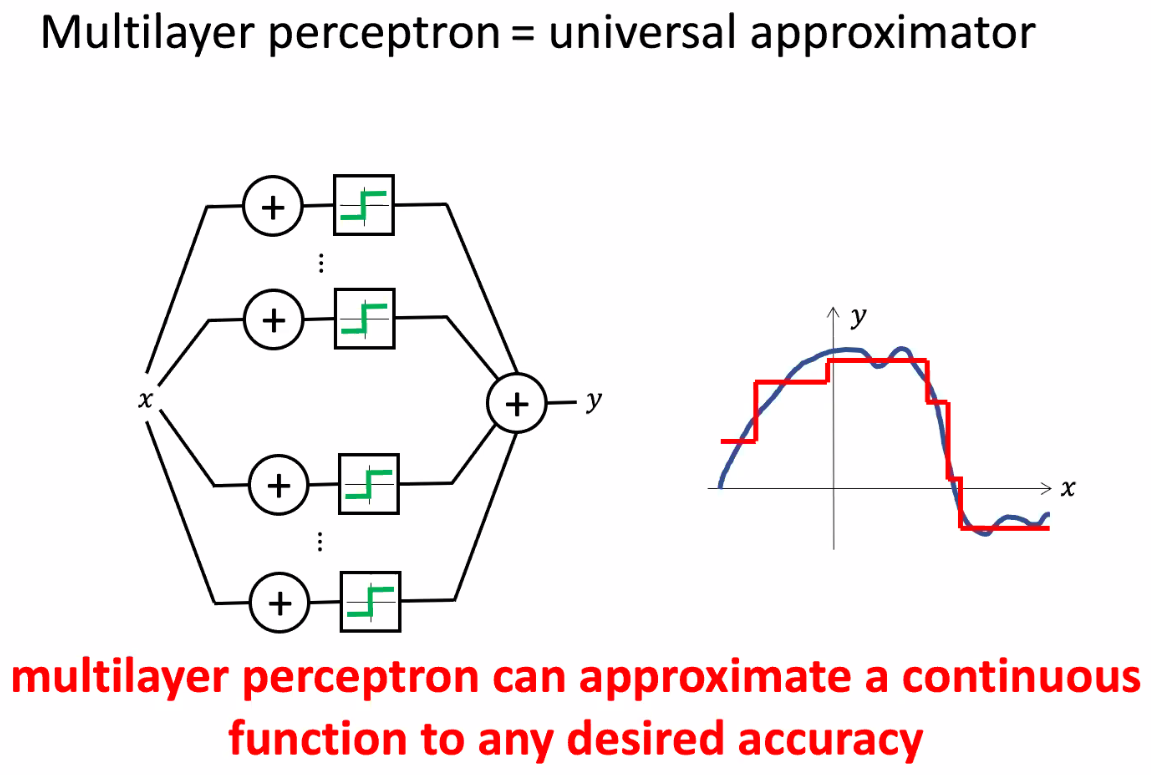
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./Dataset_spine.csv')
df = df.drop(['Unnamed: 13'], axis=1)
Given data for classification task¶
df.head(4)
df.describe()
df = df.drop(['Col7','Col8','Col9','Col10','Col11','Col12'], axis=1)
Data after preprocessing and feature selection¶
df.head(4)
MLP Classifier¶
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
y = df['Class_att']
x = df.drop(['Class_att'], axis=1)
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size= 0.25, random_state=27)
clf = MLPClassifier(hidden_layer_sizes=(64,128,32),max_iter=300, alpha=0.0001, solver='sgd',
verbose=10,random_state=21,tol=0.000000001)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print(accuracy_score(y_test, y_pred))
Model parameters and the target¶
print(clf.coefs_[0].shape)
print(clf.coefs_[1].shape)
print(clf.coefs_[2].shape)
print(clf.coefs_[3].shape)
print(clf.classes_)
MLP regressor¶
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=2000,n_features=10, random_state=1)
data_ = np.hstack((X,y.reshape(-1,1)))
np.random.shuffle(data_)
cols = ['Feature_'+str(i) for i in range(1, 11)]+['Target']
data_ = pd.DataFrame(data_,columns=cols)
data_.head(4)
from sklearn.neural_network import MLPRegressor
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=1)
regr = MLPRegressor(hidden_layer_sizes=(64,128,32), random_state=1, max_iter=500).fit(X_train, y_train)
print(regr.score(X_test, y_test))
Model parameters¶
print(regr.coefs_[0].shape)
print(regr.coefs_[1].shape)
print(regr.coefs_[2].shape)
print(regr.coefs_[3].shape)
Questions¶